DriveSpatial: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
1University of Arkansas, USA 2Google Research, Google 3University of Liverpool, UK 4Max Planck Research School for Intelligent Systems
Abstract
Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes.
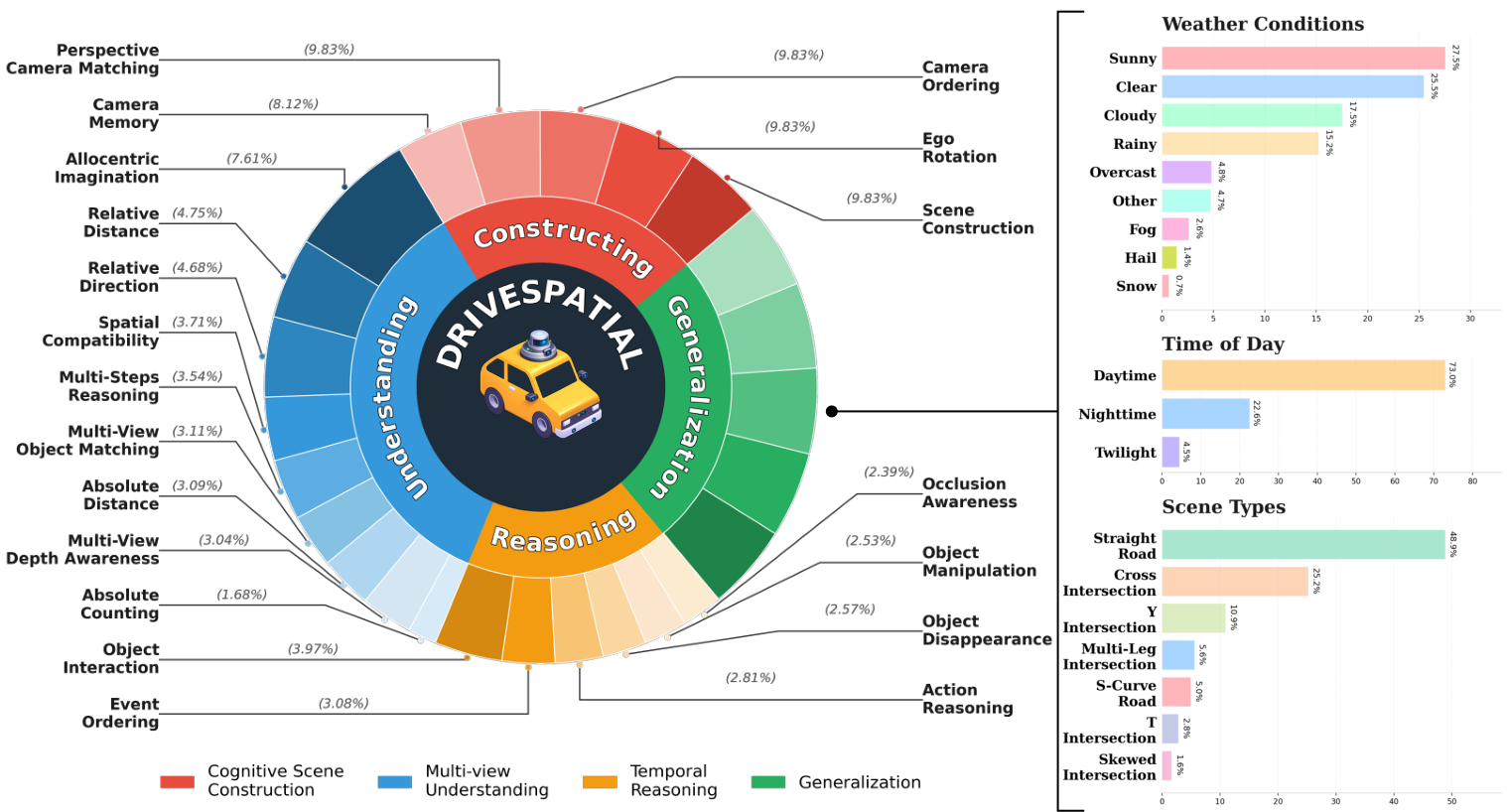
We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph encoding object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning.
Evaluating 15 representative VLMs reveals a substantial human–model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction as the key bottleneck. Language-only prompting is insufficient, while explicit BEV grounding consistently improves performance.
Question Examples
Representative samples from nine of the 20 tasks, grouped by ability. Each question requires integrating multi-view camera inputs, with correct answers shown in green in the original paper.

Dataset Statistics
Built from five large-scale AD datasets — nuScenes, Waymo, TruckScenes, AV2, and ONCE — spanning car and truck platforms across diverse weather conditions, scene layouts, and times of day.
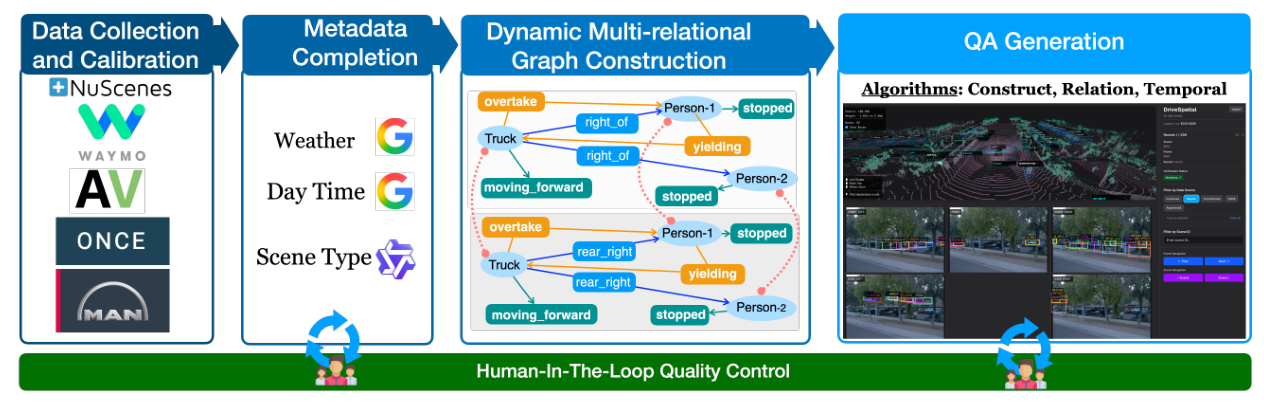
Benchmark Construction Framework
DriveSpatial is built through a four-stage pipeline with human-in-the-loop verification at both the metadata and QA generation stages.
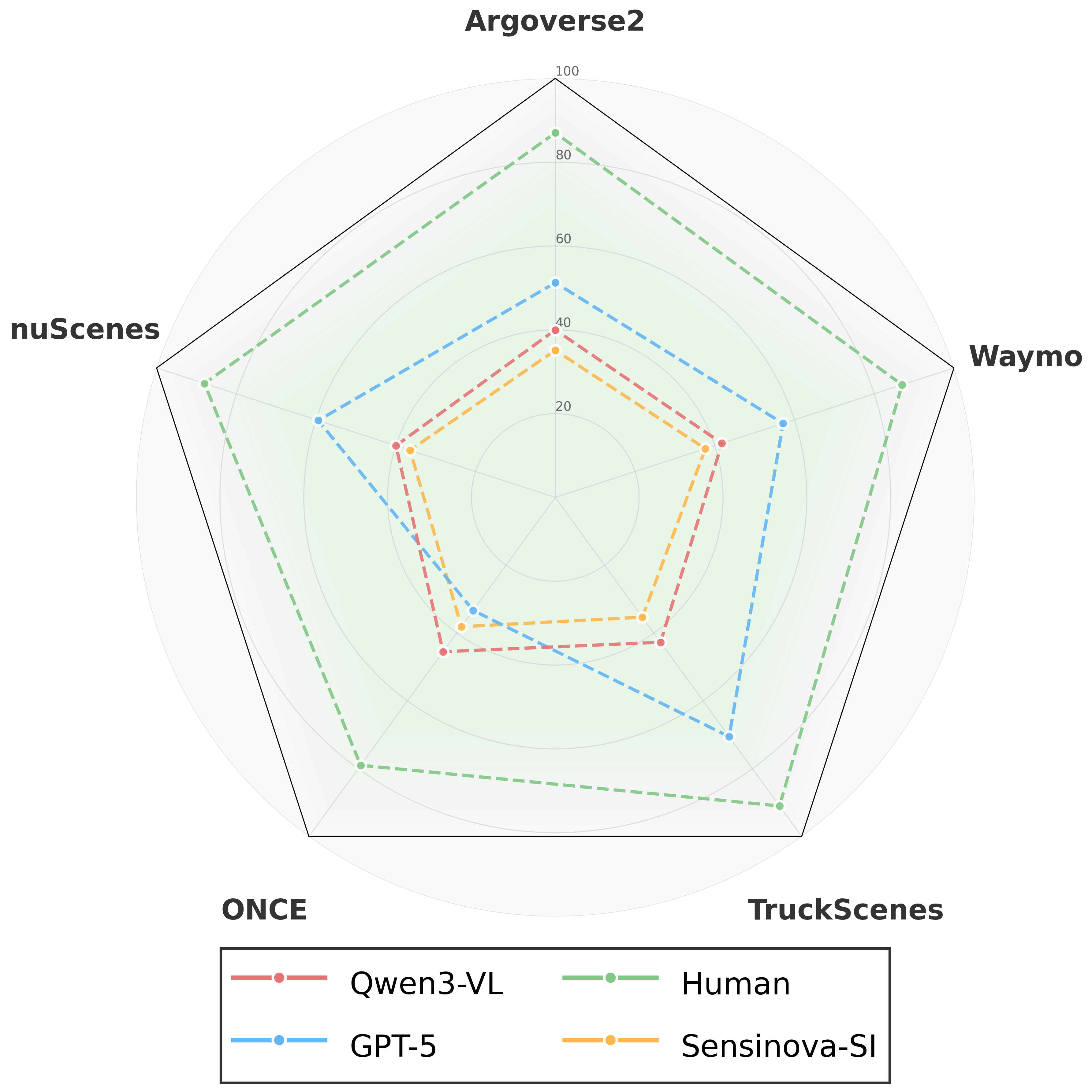
Main Results
Results on DriveSpatial for 15 VLMs across three model groups. Human upper-bound is measured on DriveSpatial-mini (1,000 stratified questions). ‡ denotes models evaluated on DriveSpatial-mini.
| Method | Rank | Avg. | Const. Acc ↑ |
Unders. Acc ↑ |
Unders. RMSE ↓ |
Reas. Acc ↑ |
|---|---|---|---|---|---|---|
| Baselines | ||||||
| Random | 13 | 26.33 | 25.37 | 28.24 | — | 25.39 |
| Frequency | 8 | 32.45 | 32.94 | 33.89 | — | 30.51 |
| Human ‡ | 1 | 83.39 | 86.20 | 85.62 | 10.62 | 88.96 |
| Proprietary | ||||||
| GPT-4o ‡ | 3 | 51.37 | 48.22 | 59.84 | 12.71 | 58.76 |
| GPT-5 ‡ | 2 | 54.98 | 55.20 | 62.45 | 10.41 | 57.69 |
| Gemini-2 Pro ‡ | 4 | 47.26 | 44.09 | 58.51 | 13.20 | 52.38 |
| Generalist — Image-based | ||||||
| LLaVA-Onevision-7B | 10 | 28.65 | 33.73 | 27.64 | 15.76 | 40.34 |
| DeepSeek-VL2-Small | 14 | 24.88 | 23.92 | 26.60 | 15.15 | 39.26 |
| Gemma-3-12B-it | 7 | 35.25 | 35.55 | 44.05 | 14.65 | 40.80 |
| InternVL-3.5 8B | 6 | 36.73 | 39.00 | 44.15 | 14.26 | 41.31 |
| InternVL-3 8B | 16 | 24.20 | 30.63 | 27.26 | 15.95 | 30.65 |
| Qwen3-VL 8B | 5 | 42.24 | 42.76 | 50.62 | 14.32 | 47.66 |
| Generalist — Video-based | ||||||
| LongVA-7B | 12 | 25.91 | 26.84 | 35.90 | 20.26 | 35.25 |
| LLaVA-Video-7B | 13 | 25.24 | 26.94 | 27.57 | 15.68 | 36.89 |
| Specialist | ||||||
| RoboTron-Drive | 18 | 23.14 | 24.31 | 21.03 | 15.49 | 39.56 |
| Ego3D | 11 | 26.48 | 30.21 | 30.67 | 15.95 | 34.53 |
| SpaceThinker | 17 | 24.53 | 27.16 | 31.74 | 16.96 | 31.65 |
| SenseNova-SI | 9 | 30.54 | 37.91 | 36.25 | 15.25 | 32.73 |
‡ Evaluated on DriveSpatial-mini. Avg. = (Const.Acc + Unders.Acc − Unders.RMSE + Reas.Acc) / 3.
BibTeX
@article{vo2026drivespatial,
title = {DriveSpatial: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving},
author = {Vo, Hao and Vo, Khoa and Nguyen, Phu Loc and Tran, Sieu and
Nguyen, Duc Minh and Cuong, Ngo Xuan and Gawugah, Gladys and
Godavarthi, Sreevenkata Anjani Tishita and Rainwater, Chase and
Bui, Nghi D. Q. and Nguyen, Anh and Ho Nguyen, Duy Minh and Le, Ngan},
year = {2026}
}